前言
每当引入一个新的技术在项目中,一定是为了解决某个问题从而提升性能,当然不可避免的会增加维护成本以及技术本身需要考虑的问题。那么就来总结一下当项目引入了消息队列之后,需要去关注的一些常见问题
- 如何处理消费过程中的重复消息
- 如何确保消息不丢失
- 如何保证消息的顺序消费
- 消息积压了应该如何处理
如何处理消费过程中的重复消息
在消息传递过程中,如果传递失败那么发送方会执行重试,而这个重试的过程就可以会出现重复的消息。
可能会有第一直觉想到说,如果我的消息队列本身消息就是没有重复,那么业务程序不就简单多了吗?
在常见的消息队列中都是遵守At least once,也就是至少一次,消息在传递的过程中,至少会被送达一次,也就是说不允许丢消息,但是允许有少量重复消息出现。
说的这里要避免消费过程中的重复消息,本质还是需要让代码“接受”重复,也就是要让代码能过消除重复消息对业务的影响。
用幂等性来解决重复消息的问题,幂等通俗来说就是,任意多次执行产生的影响,和第一次执行的影响相同,那么如何处理消费过程中的重复消息呢?At least once + 幂等消费,那么下面就来谈谈几种常见的幂等方式。
案例:假设给账户A的余额增加100元,如何达到幂等
利用数据库的唯一约束来实现幂等
可以新建一张转账流水表,其中表中有三个字段并且创建唯一约束为转账单ID和账单ID
- 转账单的ID
- 账户ID
- 变更余额
来看看消费逻辑,同一张转账单和同一个账户只能在表中存在一个,这样就达到了幂等的效果。
- 在转账流水表中增加一条转账记录
- 根据转账记录,异步操作更新用户余额
为更新的数据设置前置条件
顺延着上面所说的唯一约束的思路,可以在变更数据的时候设置一个前置条件,当满足前置条件的情况下才进行操作。
例如向用户A的账户增加100元,那么增加一个约束,只有当用户A的账户是等于200元的时候才进行增加。在消息队列中可以这样做
- 在发送消息的时候在消息体中带上当前的余额
- 消费过程中判断数据库中的余额是否与当前准备消费的余额相等
为什么消息队列没有做到Exactly once?
- 性能问题:回到最原始的问题,为什么要使用消息队列无非就是提升性能,那么如果消息队列要实现Exactly once的特性,就必须在消费端pull数据的时候,判断是否被消费过,无疑会降低性能。
引申思考点:正如使用Redis进行缓存必然需要考虑数据一致性的问题,如果为了达到强一致性而采用锁进行,那么我认为是本末倒置了。
- 即使消息队列实现了Exactly once,但是在消费端成功消费之后,返回ack失败那么还是会导致重复消息,因此还是需要at least once + 幂等来进行处理。
如何确保消息不丢失
解决消息不丢失,前提应该是知道消息可能会在那里丢失。
- 生产阶段:消费在Producer创建出来,经过网络传输发送到Broker端
- 存储阶段:在这个阶段,消息在Broker之端存储
- 消费阶段:Consumer从Broker上拉取消息,进过网络传输到Consumer上
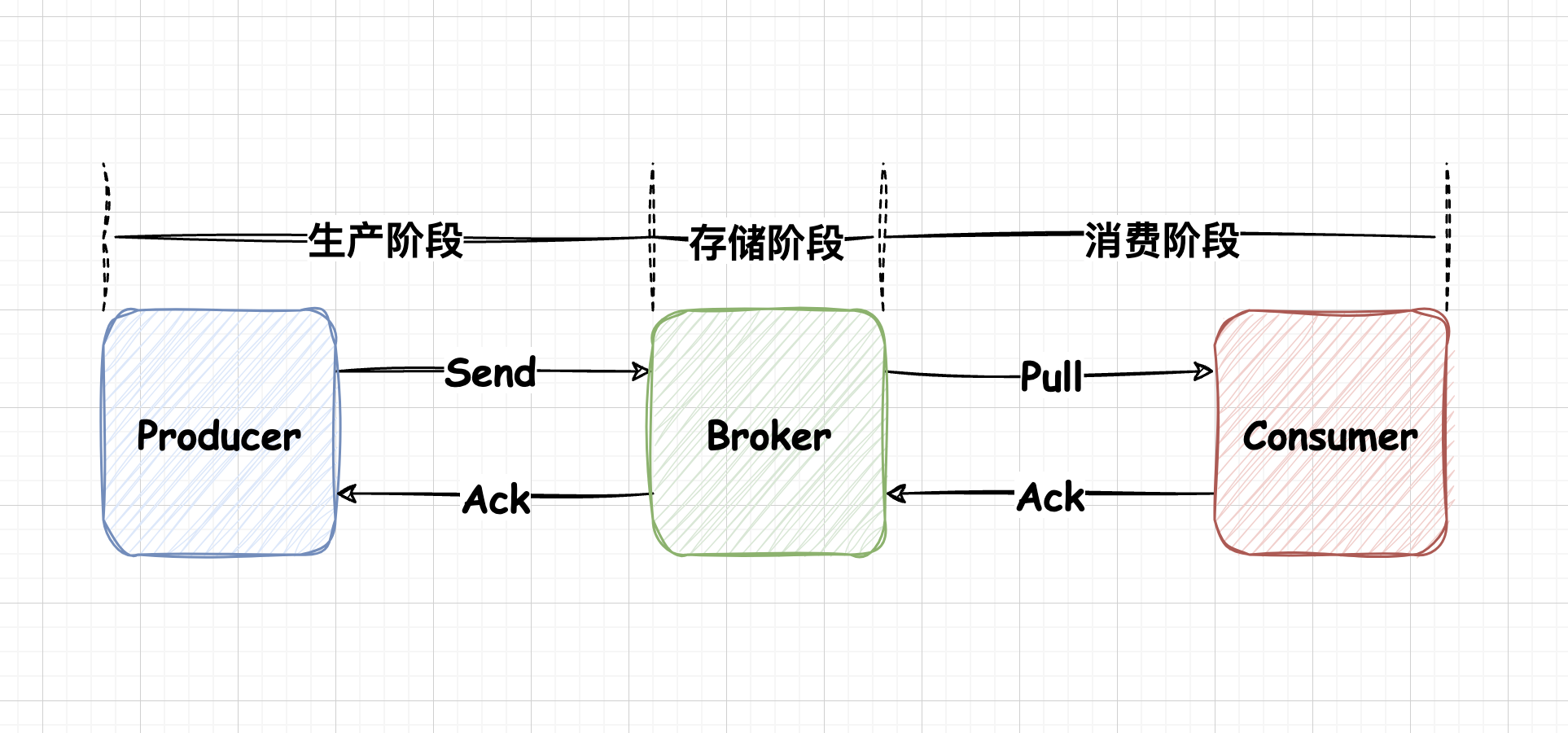
生产阶段
消息队列通过最常用的请求确认机制,保证消息的可靠传输,当Broker收到消息的时候会返回确认响应。
在代码层面上,只要正确处理返回值并且捕获对应的异常,就可以保证这个阶段消息不丢失
存储阶段
在正常情况下,如果消息能够正常的到达Broker中并且完成持久化那么消息就不会丢失。
Kafka是使用日志来做消息的持久化,日志文件是存储在磁盘上的,如果Broker在消息没有完全写入日志之前崩溃,那么消息可能会丢失。并且,操作系统在写磁盘之前,会先把数据写入到page cache中,然后操作系统自己决定什么时候同步到磁盘中,这个过程中,如果这个过程中宕机了,那么这个消息也可能丢失。
即使Kafka引入了副本机制来提升消息的可靠性,那么如果发生了同步延迟,还没有来得及同步,主副本就挂掉了,那么消息就可能发生丢失。
kafka是不能保证100%的消息不丢失(极端情况下),可以引入分布式事务等来保证在kafka Broker没有保存消息成功时,可以重新投递消息。
总结
如何确保消息不丢失?WAL!
如何保证消息的顺序消费
kafka为例
在kafka中它可以保证,在同一个的partition上是顺序消费的,但是跨partition,或者是跨topic的消息就是无序的了。
引申为什么同一个partition的消息是有序的?当生产者向某个partition发送消息的时候,消息会追加到该partition的日志文件中,并且被分配唯一一个offset,文件的读写是有顺序的,而消费者在消费的过程中,是通过offset来进行的,因此保证了消息是有序的。
那么如何实现消息的顺序消费
在一个topic中,只创建一个partition,这样就可以保证同一个partition中顺序消费了
发送消息的时候指定partition,如果一个topic有多个partition,那么可以将需要保证顺序的消息都发送到同一个partition中
如何发送到同一个partition
- 指定partition
Producer<String, String> producer = new KafkaProducer<>(getProperites());
String topic = "hello_world";
String message = "hi!";
int partition = 0;
// 创建包含分区信息的ProducerRecord
ProducerRecord<String, String> record = new ProducerRecord<>(topic, partition, null, message);
produce.send(record);
消息积压了应该如何处理
消息积压一定是在使用消息队列需要考虑的问题。
首先,消息积压的直接原因一定是,系统中某部分的性能出现了问题
如果消费端速度跟不上发送端生产消息的速度,那么就有可能造成积压,在设计系统的时候,应该保证消费端的消费性能应该高于生产端发送性能。消费端的性能优化除了优化消费业务逻辑以外,也可以通过水平扩容,增加消费端的并发数来提升总体的消费性能。
那么常见的消息积压应该如何处理?对于系统内发生了消息积压的情况,先解决积压(扩容Consumer的实例数量),再分析原因;那么常见的处理积压可以总结
- 临时扩容,增加消费端
- 服务降级,关闭非核心业务,减少消息生产
- 通过日志分析,找到积压问题
引申:消费端是否可以通过批量消费来提升消费性能?是否批量消费总体是需要结合业务的,需要注意如果使用了批量处理,需要考虑批量消费一旦某条数据消费失败会导致整批数据重复消费;业务对实时性要求不能太高,批量消费需要Broker积累到一定消费数量才会发送到Consumer